Eli Tan, reporting for The New York Times (gift link):
The company’s new A.I. image generator has a surprising twist: It
allows people to use images from public Instagram accounts.
When Meta unveiled an artificial intelligence image generator
called Muse Image on Tuesday, it came with a feature that let
users create A.I. images based on people’s Instagram photos. Any
adult with a public Instagram account was automatically opted in.
Using the Meta AI app, the company’s stand-alone chatbot, other
users could pull from “part or all of your published photos” to
create new A.I. images, the company wrote in a blog post.
This is an utterly unsurprising twist, given the entire history of the company. There are settings to turn this off (which Tan explains how to find), but to me it really does show that Meta views its users as something akin to vassals.
New Zealand startup Zenno Astronautics has completed the first orbital test of its "Supertorquer," a shoebox-sized superconducting magnet system that uses solar power and Earth's magnetic field to help control a satellite without fuel. The company says the technology could eventually support fuel-free satellite maneuvers, docking, deep-space trajectory changes, and even magnetic radiation shielding for astronauts. Space Magazine reports: The tests began shortly after Mira's launch in November last year aboard the SpaceX Transporter 12 mission and saw the shoebox-size device perform with flying colors, Zenno Astronautics CEO and founder Max Arshavsky, told Space.com. "It's a technology that allows a spacecraft to not tumble violently in space and point in the right direction," Arshavsky said. "The unit has multiple super-conducting magnets that are positioned in different axes. When we power up the magnets, they generate a magnetic field, which interacts with Earth's magnetic field, and because we can control the magnetic field on the satellite, we can control the way in which it turns with respect to Earth."
Superconducting magnets are made of coils of superconducting wire that have zero electrical resistance and can therefore conduct much larger currents than normal wires. That larger current translates into a greater magnetic force. There is, however, a catch: Superconducting materials need to be cooled to extremely low temperatures to gain their wonder properties. [...] The unit housing the superconducting magnets is wrapped in layers of insulation and fitted with a heat pump that removes all the excess heat from the system. Every time the satellite needs a push, the superconducting coils power up, drawing energy from a battery charged by the satellite's solar panels.
"It's converting solar energy straight into useful work," Arshavsky said. "Energy is the one thing that is abundant in space, and you can use it to energize the magnet to create a magnetic acceleration device. It gives you acceleration without fuel." In the future, Zenno Astronautics plans to launch larger systems that could enable spacecraft to dock in space or conduct close proximity operations using just the power of their solar-powered superconducting magnets. Arshavsky envisions powerful magnets that could, in the future, propel spacecraft on missions to the moon and Mars using only solar power.
"Magnetorquers" have been in use for LEO station-keeping for decades. But they only work in LEO because only there is the Earth's magnetic field strong enough. It's _possible_ that this new tech enables use in higher orbits, and that really would be a breakthrough, but I don't buy its being workable in deep space.
Right. I don't properly understand why myself, but magnetorquers cannot generate forces on the center of mass of the satellite, only torques. I doubt the superconducting version is any different.
sounds cool but I dunno if there's anything real there.
I searched on arxiv and google scholar for any recent publications about this, and didn't find any using the keywords that are here and in the Space Magazine article, or any similar terms I tried.
The Zenno leadership listed on their website have some scientific publications but nothing relevant to this that I spotted. For instance, one of Wieczorek's recent publications was "Classifying seizure generation mechanisms: A critical transitions framework", while Arshavsky himself doesn't have anything coming up on Scholar except "Enabling a Multi-National Commercial Destination in Space: The Port" which is a sales pitch that was delivered at something called AIAA SCITECH 2022 Forum.
Magnetic fields are quite feeble -- wikipedia describes the surface flux density relative to a "strong fridge magnet" (not even a rare earth magnet) -- and it's 150 to 450 times less intense. Surprisingly, though, it diminishes relatively little from earth surface to LEO; the dipole model suggests it would be 70% as strong at 800 miles above the earth's surface, only 12.5% further from the earth's center than the surface.
However, it's not the intensity that matters, but the magnetic pressure. Magnetic pressure is generated by the gradient in magnetic field strength. The gradient of the earth's magnetic field in LEO is quite tiny! You wouldn't worry too much about taking a kitchen magnet on a maglev train, because its gradient is so small a meter or two away where the maglev is doing its thing! But that gradient would be much stronger than the one they're proposing to use here.
My gut is telling me this probably generates quite a tiny tiny amount of thrust and I really wish there was some scientific paper adjacent to these folks to show that it's even plausible that it could be plausibly useful for the simplest proposed purpose.
Subsequently I found this in a 2025 survey on arxiv (not peer reviewed): > In Ref. Zubrin1993 , Zubrin extends the concept of the magnetic sail to near-Earth applications, investigating its potential use for escaping from LEO. The underlying physical principle is that a superconducting loop can interact not only with the solar wind but also with Earth’s magnetosphere and trapped plasma, producing thrust by deflecting charged particles and currents. The paper derives thrust estimates and evaluates efficiency, showing that while the achievable thrust in near-Earth space is small, continuous operation could gradually raise a spacecraft’s orbit and eventually enable Earth escape. The study highlights the advantages of propellantless propulsion but also notes the practical limitations and the technical challenges of deploying and maintaining large superconducting coils in orbit. In Refs. Kezerashvili2021 ; Kezerashvili2022 , a novel concept was presented for deploying a circular superconducting wire attached to a thin circular membrane. Using classical electrodynamics and elasticity theory, it was shown that the superconducting current in the wire can effectively deploy the wire into a large circular shape. https://arxiv.org/html/2510.21743v1#S5 chasing that found a copy of Zubrin 1993 at https://www.researchgate.net/publication/234453772_The_use_of_magnetic_sails_to_escape_from_low_earth_orbit which investigates a superconducting magsail 64km in diameter, and actually does calculations to show how much thrust it could supposedly develop. I'm not sharp enough to spot if this is still all just nonsense (hopefully not obvious nonsense if it's cited in a survey 30 years later!), but nobody's gonna be able to deploy a 64km object in LEO and avoid instant destruction by all the starlink junk up there anyway. If I understand right the amount of thrust generated is dependent on the 4th power of the sail diameter, so it really does need to be extravagantly large.
alternative_right shares a report from 404 Media: A software developer made a Chrome and Firefox extension called Knockoff that automatically hides, grays out, or filters products from sketchy brands on Amazon, which highlights just how many shady brands are on the platform and how commonly they show up on searches for basic items. In just a few minutes of using the extension, Knockoff dimmed product listings for screwdrivers made by "SUNHZMCKP," spoons made by "SACATR," and a lamp made by "ROTTOGOON."
In a tweet announcing the extension, developer Josh Pigford wrote "Sorry to brands like WNPETHOME, EHEYCIGA, YXYL, LU&MN, JOYIN, TOMY, GODONLIF, YOOJEE, LINGTENG, LANEIGE, VISCOO, BIODANCE, COOFANDY, BALENNZ, TOSY, and LUENX." The extension can also hide all sponsored product listings. The extension quickly went viral as a much-needed filter for people who still use Amazon and, for those who don't use Amazon because of its horrendous labor practices and other concerns, it is evidence of what an incredible wasteland the platform has become.
Of all innovations adopted by the maker community within the past couple of decades, one stands among the rest on top for anything regarding manufacturing. It goes without saying here at Hackaday how many projects have been reliant on using the technology to turn their ideas into reality. 3D printing has been a maker community invention and, in return, has expanded this hacky community into something that anyone with an imagination can get into. It also goes without saying that the layer-based tech imposes limits on what we can actually create: think overhangs and layer adhesion. However, there’s a possibility that a recent offshoot of this scrappy community has the power to eliminate some of these faults.
Volumetric additive manufacturing (VAM) is a young technology that has a similar start to many new tech toys, including the original SLA of the first 3D printers. That is expensive and completely stuck in the laboratory… Fortunately, that’s not where 3D printing as a whole stayed, as the RepRap project managed to bring the obscure technology to the hobbyists’ main stage. An entire group of people formed and spent countless hours until the useless pieces of poorly extruded plastic could form parts impossible to make with anything else. A cool quirk of history is that it likes to repeat: examples spur recreation, and this appears to be happening with the technology found within VAM printing.
History
Hold up for a second. While we have covered VAM here before at Hackaday, it’s not exactly the most well-known tech or the easiest to understand. So what is it? Starting from the beginning and simplest forms, VAM is similar to the more common SLA printing. Using a light source and light sensitive resin, both of these methods can create entire physical objects by solidifying or curing specific areas of a vat or vial of resin. SLA will often use something like a laser and layer by layer “draw” the model until the entire geometry is finished. A quirk of most of many photosensitive resins is that they need to overcome a threshold before they can start curing. This allows VAM to do something a bit different. The earliest methods of VAM used intercepting lasers which allowed selective curing only where these beams were intercepted. One singular spot at a time would be able to overcome the threshold required for printing, allowing you to build up most geometries.
Xolography Print
This works, but for more complicated models there’s more effective methods. One type has been covered here before called Xolography, still using intercepting beams, however with differing wavelengths which allows for more finite control. This is effective, but the resin is complex, requiring two-wavelength-photon-sensitive photoinitiators. Introduce the current standard in VAM printing, computed axial lithography (CAL). This method finds itself using existing methods found in traditional tomography, such as CT scanners. CAL methods are basically reverse tomography, where a model is used to create projections to be projected in printing. These projections allow dose control in each “voxel” of resin from changing the projection as the volume of resin is rotated. When ideal, this means that the entire model is printed at once. No layers needed for printing, and printing in minutes rather than hours.
Open-Sourced
Cool, but why should you care about this tech? Because you could start using it now! Just like the RepRap project before it, VAM has OpenCAL. OpenCAL was started by the same lab that originally created the axial version of the technology. UC Berkeley released the first OpenCAL around 2019 which was… well a start.
Functionally practical for only big budget research, it was far too expensive and complicated for any hobbyist with a 9-5 to realistically touch. Last year saw a new model presented at Open Sauce which used a consumer projector and common hobbyist electronics. While this was an improvement, there are three barriers to VAM printing; the hardware, software, and chemical resins make it a challenge for any individual alone. A newer version of the hardware was quickly put together for this summer. This helps with the hardware element, but there’s two new aspects being released alongside OpenCAL V2 for other unsolved problems.
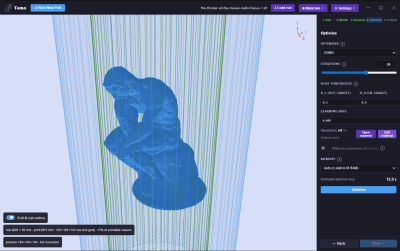
Software: Tomo
Tomo with the Thinker model being prepped
For a little while now there have been various software packages available for allowing easier use of whatever VAM printer you might have, however these had various problems. From being undocumented to being complicated for anyone without comfort in command line , something different would be needed. A standalone application would certainly work, and low and behold that’s exactly what’s being tried here, called Tomo. Tomo allows you to use an OpenCAL printer with little thought or expertise, or ideally any other type of VAM printer.
Chemistry: Formlabs Resin
Large form factor VAM print
Material science is always a particular challenge for the open source community. Unlike software, you can’t distribute unlimited copies of your perfect mix of photosensitive resin without special chemical clearances and certainly not for free. Some of the first 3D printers from RepRap would use a nylon weed wacker line in place of the standard PLA of today. Unfortunately there’s less flexibility in the fine tuned resin found in VAM. This resin has to have a nonlinear photo-reaction for selective curing, be fairly transparent to the reactive wavelength, and be very viscous to prevent resin movement during printing. Formlabs, which makes resin printers and resins, has gotten into the act. Through talks between the OpenCAL team and Formlabs, an agreement for production of this special resin is being worked out, allowing for far cheaper material.
Hardware: OpenCAL
OpenCAL V2 printer
Of course this leaves the printer itself. OpenCAL is designed for a variety of different sized printing volumes, projectors, or anything else you might have in mind. Expect printing anything from this printer to finish in the span of minutes. While it can do the same small prints found in the older model of OpenCAL, experiments involving larger form factors have been attempted. But if you want more details make sure to check out the documentation here or join their Discord channel!
Future of VAM Printing
So how far can this technology really go? Could it pass traditional methods of 3D printing? Well, it’s certainly faster than traditional printing, however, there’s still plenty of trouble when trying it out. How do you remove partially cured resin off your print? How do you actually tell when the print is done? These are problems that are being fixed right now by the community, and maybe you can be the one to fix something holding it back. It’s fair to say that the community that has propped this technology up to where it currently stands is who is going to decide where it goes.
About a month ago, Flathub announced a ban on slopcoded applications. Evangelos “GeopJr” Paterakis, developer of a number of popular Linux applications and ton of other things, did some research into just how many applications tagged with “AI slop”, a tag Flathub reviewers used to keep track of slopcoded applications submitted to Flathub, actually survived the test of time. The results are exactly what you’d expect.
Of the 120 unique repos, 32 were maintained and 88 were abandoned. No seriously, a big portion of them was completely deleted, nowhere to be found, others stopped 6 months ago, right after submitting to Flathub.
That’s absolutely soul-crushing. Why should Flathub’s reviewers spend their precious, limited time talking to lazy slopcoders’ “AI” agents to get their slopcoded applications into Flathub, when 70% of these applications are abandoned or outright deleted from existence within mere months of being submitted? Minimal effort for the slopcoders, maximum effort for the reviewers. Just dump a bunch of shitty code over the fence, let a chatbot handle the interactions with the reviewers, and pretend you made a valuable contribution.
This is the contradiction slopcode enthusiasts really don’t want to talk about. If these “AI” tools are so great, where is all the amazing new software? Where’s the massive gains in software quality? Isn’t the story that “AI” tools do the menial work, giving programmers more time to focus on improving their software? Reality does not seem to match the story we’re being sold. Despite these slopcode tools being out and available for years now, there’s no influx of great applications and other software, there’s no rise in software quality, nothing.
What we mostly seem to be getting are slopcoded projects nobody, not even their “creators” care about, so they just get abandoned and deleted as quickly as they were dredged up from the bottom of the programming barrel. These aren’t applications created because someone wanted them to exist; these are applications created because some mid programmer got high on their “AI” supply and fancied themselves better at programming than they really are – only to realise once the comedown hits they’ve got crappy, barely working, entirely unmaintainable gibberish vaguely looking like code nobody can make head nor tails of.
And then they abandon the project, ready for the next high – leaving everyone else to clean up their mess.
"What we mostly seem to be getting are slopcoded projects nobody, not even their “creators” care about, so they just get abandoned and deleted as quickly as they were dredged up from the bottom of the programming barrel."
Blood pressure is one of the so-called “vital signs” that medical practitioners use to determine the basic state of a patient in any given moment. It’s exactly what it sounds like—a measurement of the pressure of the blood flowing through the body, with some complications to account for the pulsatile nature of human blood flow.
You might think measuring blood pressure is a solved concern, and it mostly is. With that said, some blood pressure monitors out there aren’t quite doing their job properly, and [Milos Rasic] came to Hackaday Europe 2026 to spell out the problem.
Under Pressure
Before exploring the issue, it’s worth first understanding how blood pressure is actually measured. On a baseline level, it’s the same as pressure being measured in any other fluid. Specifically, though, when it comes to blood, it’s important to measure the pressure at two points. There is the peak, when the heart muscle is contracting, referred to as systolic pressure, and the low point, when the heart relaxes, referred to as diastolic pressure. Thus, blood pressure is referred to with two numbers, such as “140 over 90” or 140/90, referring to systolic and diastolic pressures respectively. It’s sometimes important to track the mean arterial pressure, too. Typically, nominal blood pressure would be considered around 120/80 mmHg. High blood pressure, or hypertension, starts at figures over 130/80 mmHg, while low blood pressure, or hypotension, would be considered relevant below 90/60 mmHg.
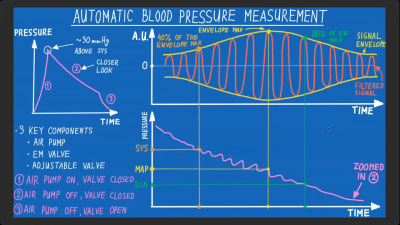
Blood pressure can be monitored in a number of ways. Most of the time, non-invasive methods are preferred, whether in the doctor’s office or at home. [Milos] notes that the classic hand-pumped blood pressure cuff device (sphygmomanometer) and a stethoscope is still a perfectly excellent way to measure blood pressure in a clinical scenario. This is referred to as the Korotkoff method, where the doctor listens for pulsations in the artery to begin as the pressure of the cuff slowly drops below the systolic pressure, and then later ease as it reduces below the diastolic pressure, monitoring pressure in the cuff on a gauge as they go. Then there are digital versions of arm cuff blood pressure monitors, which [Milos] notes can have some problems. Meanwhile, there are advanced technologies in development to do live measurement with things like mmWave radar devices or ultrasonic tricks, but they’re still emerging and less established in clinical contexts.
Many cheap electronic blood pressure monitors use the oscillometric method to measure blood pressure. Few manufacturers share the algorithms they use, but [Milos] has found many use something similar to the above, approximating systolic and diastolic pressures from measurements taken to find the mean arterial pressure. Credit: presentation slides[Milos’s] talk focuses on the digital oscillometric analysis that is behind cheap electronic blood pressure monitors that commonly retail for $30-50. These devices start by pumping up an arm cuff to well above typical systolic pressures, before slowly letting it deflate. A sensor hooked up to the cuff is used to monitor the pressure during deflation. When the cuff is below systolic pressure but above diastolic pressure, the pressure in the cuff will oscillate with the pulsing of the blood flow. When isolated from the overall pressure loss from deflation, the amplitude of this oscillatory signal is maximum at the mean arterial pressure. According to [Milos], it’s common for electronic blood pressure monitors to then take some figure like 40% and 80% of the amplitude of the oscillation envelope, and grab the systolic and diastolic pressure values at those points. As far as accuracy goes, this method isn’t exactly perfect, being more of a useful approximation rather than something that’s rooted in a true direct measurement. Furthermore, [Milos] notes that, for example, Category A blood pressure monitors are only expected to land within a +/- 15 mmHg range, for 85% of their measurements. That’s not fantastic.
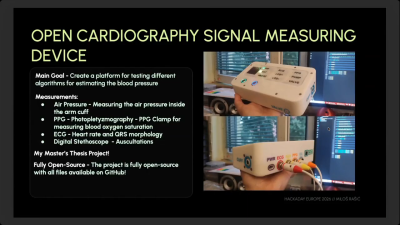
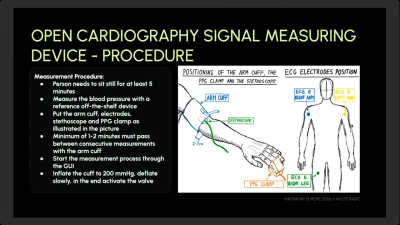
[Milos] has invested a great deal of time into the Open Cardiography Digital Measuring Device, hoping to better investigate alternative methods of measuring blood pressure in a non-invasive manner.[Milos] notes that it’s important to allow the patient to sit still for five minutes before measurement if numbers are to be at all comparable between checks, as many factors can influence blood pressure in the moment.The method used by these electronic devices tends to be a little inaccurate compared to the traditional clinical methods performed by trained professionals. For that reason, [Milos] developed the Open Cardiography Signal Measuring Device. It is specifically designed to test different algorithms for blood pressure measurement. It can measure pressure in an arm cuff, and also takes signals from a photopletyzmography (PPG) clamp for measuring blood oxygen saturation. There are also inputs for ECG and digital stethoscope signals, too. [Milos] has published the device’s design on Github for anyone to explore as desired. His talk explains how the device came together, and how he has been using it to evaluate the accuracy of off-the-shelf monitors and the use of alternative algorithms to those used in such units. He also discusses the challenges of measuring blood pressure accurately in this way when dealing with, for example, patients with less stable heart rates.
It’s an interesting exploration of a very specific part of vital sign measurement that few of us ever think about in detail. Sometimes it pays to know how the machines that you’re getting measurements from actually work, and whether you can trust what they’re saying. In the world of blood pressure measurement, [Milos] has done just that.